Domain model¶
The Text Repository was born out of the desire to archive and unlock text corpora and their various files and formats in a durable and consistent way.
To represent text corpora in a generic way, the Text Repository is build around the following core concepts:
- document: top level object which represents the core physical entity of a digitized corpus (e.g. a page) that resulted in scans, xml-files, text files and other file types. A document contains a list of files, unique by file type
- file: as found on your computer, including a file type but without its contents. A file contains a list of versions
- version: version of a file. A version contains the bytes of a file and a timestamp. A file can have a number of different versions
- metadata: documents, files and versions can contain metadata in the form of list of key-value pairs
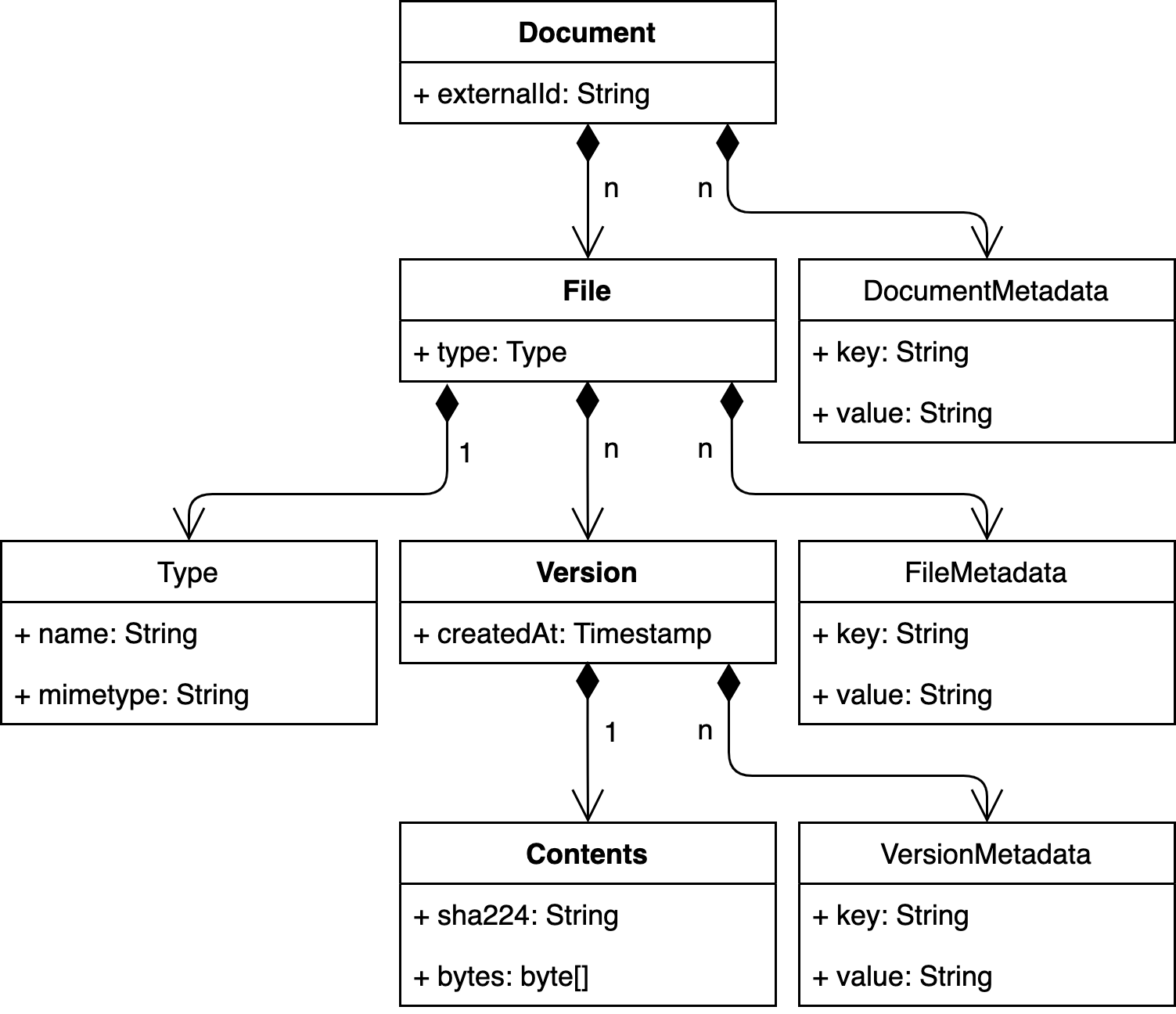
Graphical representation of the Text Repository domain model
File types¶
The Text Repository is built to contain ‘human readable’ file types that can be processed by elasticsearch, like plain text, json, and xml.
Work in progress¶
Note that this project is work in progress. The Text Repository model of a text corpus will improve and expand as the project progresses.